



Un fantástico estudio publicado en Columbia Journalism Review y titulado «AI Search Has A Citation Problem«, pidió a ocho algoritmos generativos que ya todos conocemos (ChatGPT, Perplexity, Perplexity Pro, Deepseek, Copilot, Grok 2, Grok 3 y Gemini) que localizasen el artículo, la publicación y la URL de una serie de citas obtenidas de un total de doscientos artículos, diez de cada una de veinte fuentes diferentes.
Los investigadores eligieron frases de esos artículos que podían ser fácilmente localizadas entre los tres primeros resultados de una búsqueda en Google, y se dedicaron a contar en cuántas ocasiones los algoritmos generativos respondían correctamente a esas búsquedas y ofrecían un resultado correcto, parcialmente incorrecto, completamente incorrecto, o simplemente no respondían.
Los resultados, como era de esperar y como seguramente sepa cualquiera que utilice con cierta frecuencia algoritmos generativos, es para horrorizarse. Las citas bibliográficas y las URLs están entre las cuestiones que más errores producen en las respuestas de este tipo de algoritmos, porque son cadenas de texto – sobre todo en el caso de las URLs – muy difíciles o imposibles de predecir mediante la metodología que siguen los algoritmos generativos, lo que suele llevar a que simplemente presenten un título muy sugerente que te lleva a pensar «sí, sin duda este es el artículo que necesito», para encontrarte inmediatamente al buscarlo con que ni el enlace que te ofrece funciona, ni el artículo existe por mucho que te apeteciese encontrarlo: es únicamente el resultado de que el algoritmo flipe en colores, se fume un porro y alucine pepinillos.
Los resultados fueron los siguientes: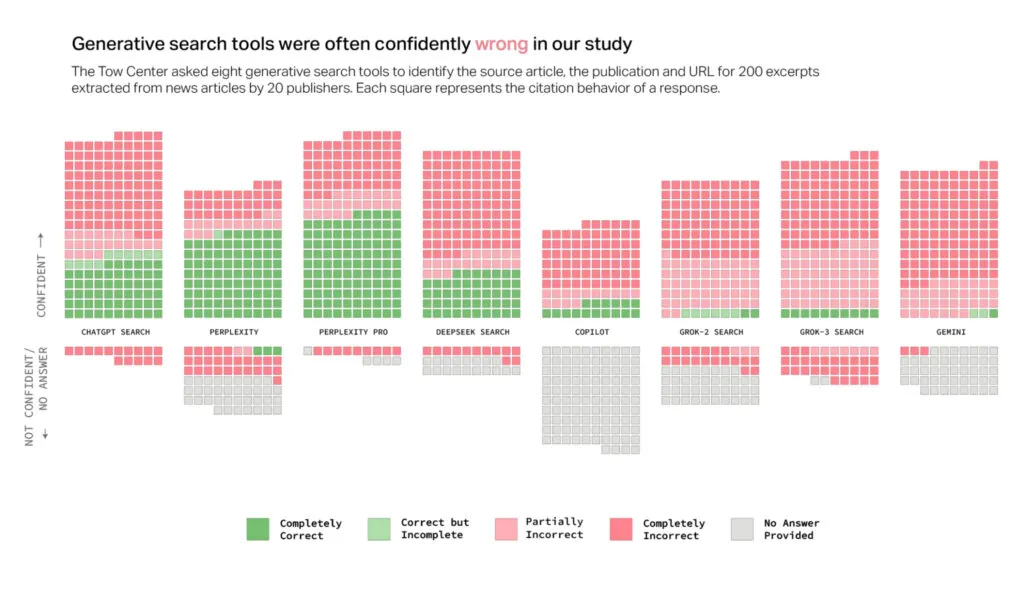
Podemos ver claramente cómo la totalidad de los algoritmos generativos cometen un número elevadísimo de errores en esa tarea concreta, con Perplexity en sus dos versiones y ChatGPT encabezando el ranking de resultados correctos, pero aún así, con una enorme cantidad de resultados incorrectos presentados como correctos con una supuesta gran confianza. Pero esos resultados, a pesar del enorme riesgo que suponen si alguien se dedica a fiarse y a interpretarlos como correctos sin comprobación, son muchísimo mejores que los obtenidos por las dos versiones de Grok o por Gemini, que tienden a equivocarse prácticamente en todas las ocasiones. Copilot, por su parte, además de equivocarse mucho, no responde en más de la mitad de los casos.
Los resultados coinciden en general con mi experiencia de uso, y con la que he podido ir comprobando en el caso de muchos de mis alumnos cuando entregan sus trabajos (en los que les autorizo expresamente a utilizar algoritmos generativos). Los chatbots generativos, en general, no son para nada buenos a la hora de negarse a responder preguntas que no son capaces de responder con precisión, y en su lugar, tienden a ofrecer en un número sorprendentemente elevado de ocasiones respuestas incorrectas o especulativas. Si no dedicas, como dije al principio de la popularización de este tipo de herramientas, un tiempo significativo a comprobar los resultados que te han entregado, tendrás problemas de inexactitud con total seguridad, más tarde o más temprano.
Además, y curiosamente, las dos versiones premium evaluadas (Perplexity Pro y Grok 3, en el momento de llevar a cabo el estudio) manifiestan una gran tendencia a brindar respuestas incorrectas con mayor seguridad que sus contrapartes gratuitas.
También resulta llamativo que varias de estas herramientas parezcan eludir completamente las preferencias expresadas en el protocolo de exclusión de robots, y que fabriquen enlaces y citen versiones sindicadas y copiadas de artículos. Curiosamente, el hecho de que las compañías que producen esos algoritmos generativos tengan acuerdos de licencia de contenidos específicos con algunas de las fuentes de noticias utilizadas no brinda garantía alguna de que las de citas que proporcionan en sus respuestas sean más precisas.
¿Invalida esto a los algoritmos generativos? En absoluto, en primer lugar porque cabe esperar que vayan mejorando con el tiempo, y en segundo, porque la búsqueda de bibliografía y citas no es para nada el uso más habitual de este tipo de algoritmos. Sabiéndolo, lo mejor es optar por motores de búsqueda convencionales cuando se pretende llevar a cabo ese tipo de tareas, y simplemente dejar a los algoritmos generativos que hagan otras cosas que sí hacen sensiblemente bien. Si no quieres perder miserablemente el tiempo, no pidas referencias bibliográficas ni citas, porque muchas de ellas serán inventadas y completamente falsas. Como de hecho sabemos perfectamente y comprobamos todo el tiempo todos los que nos dedicamos a la docencia y a la investigación. Pero una cosa es verlo y saberlo, y otra muy distinta comprobarlo en un artículo experimental.
Nota: https://www.enriquedans.com/
Te puede interesar











Lo más visto




